Building NMT for Languages the World Forgot: Achieving SOTA with Maithili and Konkani
Introduction
Building effective neural translation models typically requires massive parallel datasets - a luxury most of the world’s languages simply don’t have. When the Indian Parliament initiated translation of proceedings into 22 regional languages, Maithili and Konkani presented the most fascinating challenge. With existing models barely scraping 0.3 BLEU scores, these extremely low-resource languages seemed nearly impossible to crack. By creating synthetic datasets and leveraging cross-lingual relationships, we pushed performance to 9.5+ BLEU - achieving state-of-the-art results with minimal resources. But why exactly were these languages so challenging to begin with?
Problem Setup
To understand the scale of our challenge, consider the data landscape for English translation pairs: German has around 50 million sentence pairs, Hindi has roughly 5 million, while Tamil and Telugu have around 500,000 each. Assamese, already considered low-resource, has about 50,000 pairs. In comparison, Konkani had 5,000 parallel sentences available, and Maithili had 500.

Maithili, spoken in Bihar and Nepal, is linguistically related to Hindi, while Konkani, used in Goa and coastal areas, is connected to Marathi. These relationships offered potential for transfer learning. But the lack of native speakers internally, reliable benchmarks, and clean parallel data added challenges. However, all languages used Devanagari script, simplifying preprocessing. Before diving into our methods, it’s worth understanding the encoder-decoder architecture that underlies modern NMT.
Encoder-Decoder Primer
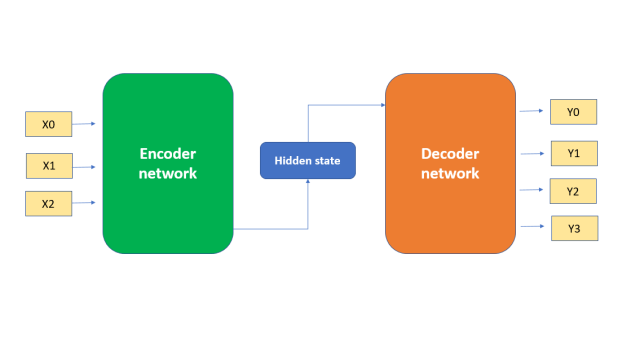
Neural machine translation relies on the encoder-decoder architecture, where an encoder module processes the input text in the source language and captures its semantic essence in vector form - essentially creating a numerical representation of the meaning. This encoded representation is then passed to the decoder module, which generates the translation in the target language through conditional next-token prediction, building the output one word at a time based on what it has already generated and the source encoding. Put simply, the encoder focuses on understanding meaning, while the decoder focuses on expressing that meaning in a new language.
The human parallel is striking: just as we can understand broken speech but struggle to speak fluently in a new language, encoders tolerate noise better than decoders. This creates an important asymmetry for low-resource NMT - source-side imperfections are manageable, but target-side noise directly degrades generation quality and makes pattern learning harder. Understanding this trade-off became central to our approach for Maithili and Konkani. Let’s see how these insights shaped our methodology.
Key Methods: Tagged Back-translation & Cross-lingual Transfer
Extreme data scarcity pushes us toward creative solutions in low-resource NMT. Two techniques that become essential are tagged back-translation and cross-lingual transfer. We’ll examine these methods in general first to establish a clear foundation.
Tagged Back-translation
Imagine you’ve trained a model on your available parallel corpus and reached a performance plateau. You have additional monolingual data in the target language but no corresponding source translations. Tagged back-translation addresses this by reverse-translating the monolingual target data to create synthetic parallel pairs. However, since back-translation introduces potential noise and artifacts, we need a way to signal this to the model during training.
Without guidance, the model cannot distinguish between original parallel data and synthetic back-translated data, potentially learning confused representations. Tags solve this by explicitly signaling data quality. We add <bt> tokens to the source side of back-translated pairs, warning the model that this input may contain noise or translation artifacts. This teaches the model to be more tolerant of potential errors on the input side. The approach aligns with our encoder-decoder asymmetry insight - encoders can handle noisy input better than decoders can handle noisy targets, so we signal noise on the source side only.
In practice, training data combines both original and back-translated pairs:
Original parallel data:
Source: “The weather is beautiful today”
Target: “आज मौसम बहुत सुंदर है”
Back-translated synthetic data:
Source: <bt> “The weather today is beautiful”
Target: “आज मौसम बहुत सुंदर है”
At inference time, no tags are needed since you provide clean, human-written source text.
Cross-lingual Transfer
Cross-lingual transfer leverages the linguistic relationships between related languages through joint training. Consider training a single model on both Hindi and Marathi data simultaneously. Despite being distinct languages, they share significant commonalities - overlapping vocabulary (पानी/पाणी for water), similar grammatical structures, and common root forms. During joint training, the model discovers these shared patterns and learns representations that benefit both languages, with the lower-resource language typically gaining more from this knowledge transfer. This works because related languages exist in overlapping semantic spaces, allowing the model to exploit commonalities for improved performance.
In practice, joint training uses language-specific target tags. Training data looks like this:
Training examples:
“I am going to school” → <hi> “मैं स्कूल जा रहा हूँ”
“I am going to school” → <mr> “मी शाळेत जात आहे”
At inference, we control the target language by prefilling with the appropriate tag:
Input: “The weather is nice today”
Directed output (Hindi): <hi> “आज मौसम अच्छा है”
Directed output (Marathi): <mr> “आज हवामान चांगले आहे”
These techniques form the foundation of our approach. Now let’s explore how we adapted them to tackle the extreme challenges of Maithili and Konkani translation.
Adapting Techniques to Extreme Low-resource Settings
Applying these techniques to Maithili reveals a fundamental challenge. Traditional cross-lingual transfer requires sufficient English-target language parallel data for joint training, yet we only had 500 English-Maithili sentence pairs. Tagged back-translation presents an even thornier problem: it requires a reverse translation model (Maithili-English) to generate synthetic data, but training such a model demands the very parallel data we lack. This creates a circular dependency - we need substantial parallel data to build the tools that help us work with limited parallel data.
The breakthrough came from recognizing that Maithili and Hindi share deep linguistic connections - both use Devanagari script, have similar grammatical structures, and many common root words. This suggested we could treat Maithili as ‘noisy Hindi’ for computational purposes. If a Hindi-English model could reasonably understand Maithili text as imperfect Hindi, it could back-translate it to English. We scraped monolingual Maithili content from news websites and used our existing Hindi-English model to reverse-translate it, creating synthetic English-Maithili pairs that preserved the natural Maithili language patterns.
This gave us three distinct data types for joint training, each with specific tagging strategies. The Hindi dataset was orders of magnitude larger than our Maithili data:

• English-Hindi pairs (clean, large dataset):
Source: “The weather is nice today”
Target: <hi> “आज मौसम अच्छा है”
• English-Maithili pairs (original 500 sentences):
Source: “The weather is nice today”
Target: <mai> “आजक मौसम नीक अछि”
• English-Maithili pairs (back-translated from scraped news):
Source: <bt> “The weather is nice today”
Target: <mai> “आजक मौसम नीक अछि”
This combination allowed us to leverage Hindi’s abundant data while teaching the model to handle potentially noisy inputs and learn Maithili generation patterns.
Given the massive imbalance between Hindi and Maithili data volumes, we employed oversampling to ensure adequate Maithili representation during training. We structured batches so that Maithili sentence pairs constituted a significant minority of each batch, preventing the model from being overwhelmed by Hindi examples. After initial joint training, we experimented with fine-tuning exclusively on Maithili data for additional steps, but observed no significant performance improvements. This suggested that the joint training approach had already effectively captured the cross-lingual patterns, and additional Maithili-only training provided diminishing returns.
Results & Insights
We evaluated our approach on the Flores-200 dataset, a commonly used benchmarking dataset for multilingual neural machine translation. Our model achieved 9.5+ BLEU scores for English-Maithili translation, representing a dramatic improvement from the 0.3 BLEU baseline of existing approaches. At the time of our work, no dedicated open-source or commercial models existed for these language pairs, making this a clear state-of-the-art achievement for extremely low-resource translation.
Two insights proved particularly valuable for practitioners working with similar constraints. First, treating linguistically related low-resource languages as ‘noisy’ versions of their higher-resource relatives enables creative workarounds for data scarcity - our Hindi-Maithili approach could readily extend to other language pairs with similar relationships. Second, strategic oversampling ensures the model encounters low-resource language pairs in every batch during joint training, preventing it from being overwhelmed by high-resource examples and maintaining adequate representation for minority languages even with extreme data imbalances.
Conclusion
Building NMT models for extremely low-resource languages requires creative problem-solving when traditional approaches fall short. By treating Maithili as ‘noisy Hindi’ and Konkani as ‘noisy Marathi,’ then combining tagged back-translation with cross-lingual transfer, we transformed an intractable challenge into an engineering solution. These techniques provide a practical roadmap for other underrepresented language pairs, demonstrating that innovative application of existing methods can achieve meaningful results even with just hundreds of parallel sentences.